Apache Spark is an industry-leading platform for big data processing and analytics. With the increasing prevalence of unstructured data—documents, emails, multimedia content—deep learning (DL) and large language models (LLMs) have become core components of the modern data analytics pipeline. These models enable a variety of downstream tasks, such as image captioning, semantic tagging, document summarization, and more.
However, combining GPU-intensive DL with Spark has historically been a challenge. The NVIDIA RAPIDS Accelerator for Apache Spark and Spark RAPIDS ML library enable seamless GPU acceleration, but primarily for extract, transform, and load (ETL) and traditional machine learning (ML) workloads.
Recent Spark APIs for distributed training and inference—described in a previous blog—made significant strides for DL integration. This post builds upon that work, introducing best practices for distributed inference on Spark. We’ll demonstrate integration with serving platforms such as NVIDIA Triton Inference Server, performant LLM inference with vLLM, and deployment on cloud platforms.
Why batch inference?
While real-time inference is best suited for interactive applications, batch inference offers a scalable, high-throughput paradigm to process massive datasets all at once. Some key use cases include:
- Semantic Search: Generate embeddings and semantic metadata for large content repositories in bulk, improving search quality.
- Data Transformation: Translate, summarize, or convert unstructured datasets—such as free-form text or images—into structured schemas for downstream tasks.
- Content Creation: Automatically generate product descriptions, image captions, social media posts, or marketing copy for large-scale content production.
Integrating DL/LLM models into existing Spark pipelines brings the capabilities of DL and generative AI directly to your enterprise data in a unified workflow. Now, let’s explore implementations, starting with a recap of Spark’s predict_batch_udf API.
Basic deployment: Distributed inference with predict_batch_udf
Spark 3.4 introduced the predict_batch_udf API, which provides a simple interface for DL model inference. This API handles automatic conversion from Spark DataFrame columns into batched NumPy inputs, as well as caching models on Spark executors. For more details, see Distributed Deep Learning Made Easy with Spark 3.4.
For example, the following code demonstrates how to use Huggingface Sentence Transformers to perform distributed text embedding on a Spark DataFrame containing text data:
from pyspark.sql.functions import predict_batch_udf
from pyspark.sql.types import *
def predict_batch_fn():
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("paraphrase-MiniLM-L6-v2", device="cuda")
def predict(inputs):
return model.encode(inputs)
return predict
embed_udf = predict_batch_udf(predict_batch_fn,
return_type=ArrayType(FloatType()),
batch_size=128)
df = spark.read.parquet("/path/to/text_data")
embeddings_df = df.withColumn("embedding", embed("text"))
embeddings_df.write.parquet("/path/to/embeddings")
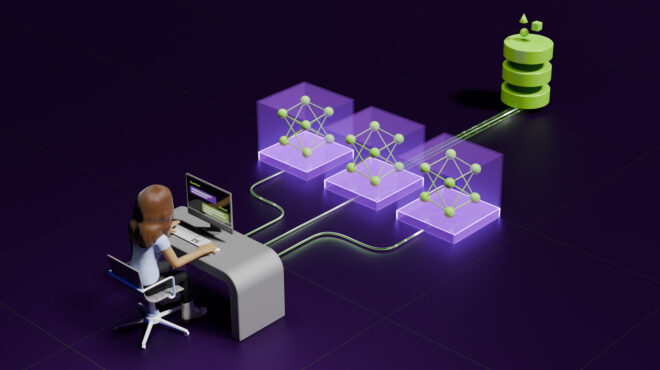
Note that this is a data-parallel architecture (Figure 1), where each Python worker loads a copy of the model onto the GPU and predicts on its partition of the dataset.


predict_batch_udf API. Each Python worker loads a copy of the model.With this direct inference approach, you can port your existing PyTorch, TensorFlow, or Huggingface framework code to Spark for distributed inference with minimal code changes.
As we’ll see, however, loading multiple model copies onto the GPU can be problematic with large models. We’ll discuss how inference serving aims to address this, providing improved resource separation.
Advanced deployment: Distributed inference serving
In the basic approach, running tasks in parallel with predict_batch_udf causes each Python worker to load a copy of the model on the GPU. As a result, you’ll have to tune the tasks per executor to determine how many model copies can run without out-of-memory errors or excessive overhead. Large models that occupy the entirety of GPU memory—such as LLMs—may require restricting to one task per executor (i.e. spark.task.resource.gpu.amount=1, for the entire application, as depicted in Figure 2).


predict_batch_udf, we must restrict to 1 task per executor.This limitation of predict_batch_udf highlights a challenge with Spark scheduling: it treats all tasks uniformly, without distinguishing between CPU and GPU resource utilization.
Inference serving solves this by decoupling GPU execution from Spark task scheduling. Instead of loading models within each Spark task, we can deploy a dedicated inference server on each executor. Many tasks can then load, preprocess, and write data in parallel to fully leverage the executor CPUs, while the server will occupy and utilize the GPU for inference, as shown below.


By providing a logical separation between CPU and GPU parallelism, inference serving avoids the need to tune the tasks per executor based on GPU memory. Additionally, it enables easy integration of serving features, such as model management and dynamic batching.
We provide server utilities in the Spark-RAPIDS-Examples DL Inference repo to launch and manage server instances across Spark clusters, with support for NVIDIA Triton Inference Server and vLLM. Note that these examples are actively evolving: we may soon expand support to inference solutions such as NVIDIA Dynamo and NVIDIA NIMs.
Serving with Triton Inference Server
NVIDIA Triton Inference Server is an industry standard platform for high-performance model serving, supporting many major features: including model ensembles, concurrent execution, and dynamic batching. Since Triton typically runs in a Docker container, deploying in cloud-based Spark environments—where executors run in containers themselves—requires Docker-in-Docker deployment, which brings challenges like privilege requirements and lack of resource isolation.
Fortunately, PyTriton provides a Python-native interface for running Triton directly within a Python process, simplifying deployment in the cloud. For a quick overview, check out this blog on PyTriton deployment basics.
The server_utils module in the Spark-RAPIDS-Examples DL Inference repo provides a TritonServerManager to manage the lifecycle of the servers across the Spark cluster: including finding and assigning available ports, starting a server process on each executor, and handling graceful shutdown after inference.
With this class, the steps to deploy Triton servers are simple:
- Define a
triton_serverfunction with the PyTriton server logic, containing your inference framework code. - Initialize the
TritonServerManagerwith your model name and path. - Call
TritonServerManager.start_servers(triton_server), which distributes thetriton_serverfunction across the cluster.
We’ll walk through these steps below. First, define the triton_server function. We’ve omitted this for brevity—see the notebooks for plenty of examples in the framework of your choice.
def triton_server(ports: List[int], model_path: str):
# Load model to GPU, define inference logic, bind to server
Once the server logic is defined, initialize the server manager with the model name and path, and pass the triton_server function when launching the servers:
from server_utils import TritonServerManager
server_manager = TritonServerManager(model_name="my-model", model_path="path/to/my-model")
server_manager.start_servers(triton_server)
host_to_grpc_url = server_manager.host_to_grpc_url
The ServerManager on the driver dises a startup task to each executor, which spawns a Python process running the user-defined triton_server function, as shown in Figure 4.


ServerManager start_servers() function initiates deployment of the triton_server process on each executor. Then, use the predict_batch_udf to preprocess a batch of inputs and send an inference request to the server using PyTriton’s ModelClient API.
def triton_predict_fn(model_name, host_to_url):
import socket
from pytriton.client import ModelClient
url = host_to_url.get(socket.gethostname())
def infer_batch(inputs):
with ModelClient(url, model_name) as client:
# Do some preprocessing...
result_data = client.infer_batch(inputs) # Send batch to server
return result_data["predictions"] # Return predictions
return infer_batch
predict_udf = predict_batch_udf(partial(triton_predict_fn, model_name="my-model", host_to_url=host_to_grpc_url),
return_type=ArrayType(FloatType()),
batch_size=32)
# Run inference
df = spark.read.parquet("/path/to/my-data")
predictions_df = df.withColumn("predictions", predict_udf(col("data")))
predictions_df.write.parquet("/path/to/predictions.parquet")
# Once we're finished, stop servers
server_manager.stop_servers()
Notice that the loading and preprocessing performed in the UDF on the CPU is now decoupled from inference on the GPU—Spark can freely schedule these tasks in parallel without creating additional copies of the model in GPU memory.
Serving with vLLM Serve
While Triton excels at handling custom inference logic, multiple frameworks, and diverse model types, vLLM is a straightforward serving alternative specifically optimized for LLMs. It provides an OpenAI-compatible HTTP server for production deployments.
We support vLLM serving on Spark via the VLLMServerManager in our utility class. Just like Figure 3, this approach launches a vLLM server process on each Spark executor, decoupling CPU and GPU execution. Instead of a custom server function, you can pass any of the supported vLLM CLI arguments when starting the servers:
from server_utils import VLLMServerManager
server_manager = VLLMServerManager(model_name="qwen-2.5-7b",
model_path="/path/to/Qwen2.5-7B")
server_manager.start_servers(gpu_memory_utilization=0.95,
max_model_len=6600,
task="generate")
host_to_http_url = server_manager.host_to_http_url
In a similar fashion, you can run distributed inference by sending requests to the server, in this case using an Open-AI compatible JSON format:
def vllm_fn(model_name, host_to_url):
import socket
import numpy as np
import requests
url = host_to_url[socket.gethostname()]
def predict(inputs):
response = requests.post(
f"{url}/v1/completions",
json={
"model": model_name,
"prompt": inputs.tolist(),
"max_tokens": 256,
}
)
return np.array([r["text"] for r in response.json()["choices"]])
return predict
generate = predict_batch_udf(partial(vllm_fn, model_name="qwen-2.5-7b", host_to_url=host_to_http_url),
return_type=StringType(),
batch_size=32)
# Run inference
preds = text_df.withColumn("response", generate("prompt"))
# Once we're finished, stop servers
server_manager.stop_servers()
Summary: Choosing your deployment strategy
Having explored both deployment approaches, let’s compare their strengths and tradeoffs to guide your implementation. We generally recommend the basic approach for simple prototyping, and the advanced approach for its flexibility and clean resource separation, as summarized in the table below.
Consideration | Basic Deployment (predict_batch_udf) | Advanced Deployment (Inference Server) |
| Resource Management | Requires tuning task parallelism to accommodate GPU memory | No task parallelism tuning required—decouples CPU and GPU scheduling |
| Setup Complexity | Simple, directly port your framework code | Simple using ServerManager, but requires some additional client/server code |
| Inference Features | Limited to framework capabilities | Additional server-specific features (dynamic batching, model ensembles) |
| Portability | Inference code is specific to the UDF | Define inference logic once in server, reuse across online/offline applications |
| Best For | Small models, simple pipelines, and prototyping | Larger models and complex pipelines |
Deploy on cloud platforms
While our previous blog demonstrated local deployment, we’ve updated the Spark-RAPIDS-Examples DL Inference repo with everything you need to deploy DL/LLM inference workloads on CSP Spark clusters.
Cloud-ready templates
The CSP instructions provide cloud-ready templates to setup and run your workloads, targeting Databricks and Dataproc Spark environments. This includes:
- Pre-configured initialization scripts to spin-up clusters and install requisite libraries.
- Recommended Spark configurations for batch inference.
- Best practices to save and load models from cloud storage.
The notebooks are configured to work end-to-end regardless of your cluster environment with no code changes—including local standalone, Databricks, or Dataproc clusters.
Configuring GPU instances
To run the examples, we recommend A10/L4 or later GPU instances (e.g. NVadsA10 on Azure, g5/g6 on AWS, g2-standard on GCP) to ensure sufficient GPU memory. A100/H100 GPUs will be a better choice for large LLMs—for instance, Llama 70b with half-precision will run comfortably on two H100s.
Sharding the model across multiple GPUs is often required for large models, and can be accomplished in Spark clusters with multiple GPUs per node. Setting spark.executor.resource.gpu.amount=(gpus per node) will allocate the requisite GPUs to each executor, and in turn make them visible to the inference server. The model can then be parallelized by the framework: for instance, by setting tensor_parallel_size=(gpus per node) with vLLM. See the vLLM tensor parallel notebook for an example of this.
Getting started
To get started, you can browse the example notebooks, which demonstrate end-to-end Spark applications for a range of use cases—including image classification, sentiment analysis, document summarization, and more—using open-source models and datasets. To deploy these applications on the cloud, please see our guide to run on CSP platforms.